Go 知识逃逸分析
逃逸分析(Escape Analysis)是指由编译器决定内存分配的位置,不需要程序员指定。在函数中申请一个新的对象:
- 如果分配在栈中,则函数执行结束后可自动将内存回收。
- 如果分配在堆中,则函数执行结束后可交给GC处理。
有了逃逸分析,返回函数局部变量将变为可能。而且逃逸分析还和闭包有关。
1. 逃逸策略
在函数中申请新的对象时,编译器会根据该对象是否被函数外部引用来决定是否逃逸:
- 如果函数外部没有引用,则优先放到栈中
- 如果函数外部存在引用,则必定放在堆中
注意,对于仅在函数内部使用的变量,也有可能放到堆中,比如内容过大超过栈的存储能力等。
2. 逃逸场景
2.1 指针逃逸
在go 中可以返回局部变量的指针,这就是一个典型的变量逃逸案例。
package main
type Student struct {
Name string
Age int
}
func Register(name string, age int) *Student {
s := new(Student)
s.Name = name
s.Age = age
return s
}
func main() {
Register("zhangSan", 18)
}
函数Register内部的s为局部变量,值通过函数返回值返回,s本身为一个指针,其指向的内存地址是堆。
这就是典型的逃逸案例。
通过编译参数 -gcflag=-m可以查看编译过程中的逃逸分析过程:
go build -gcflags=-m
# test/cha/main
./main.go:8:6: can inline Register
./main.go:15:6: can inline main
./main.go:16:10: inlining call to Register
./main.go:8:15: leaking param: name
./main.go:9:10: new(Student) escapes to heap
./main.go:16:10: new(Student) does not escape
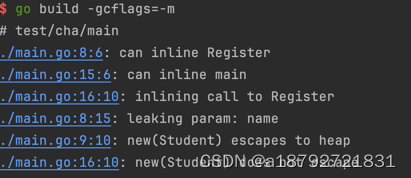
上面的escapes to heap表示在该行代码处进行内存分配时发生了逃逸现象。
2.2 栈空间不足逃逸
这个就比较好理解了,在Go语言中,每个新创建的goroutine都会获得一个小的栈,这个栈的初始大小通常是2KB。
Go语言的goroutine栈的最大大小并没有明确的限制,它主要取决于你的系统的可用内存。Go运行时会根据需要动态地增加goroutine的栈大小,直到系统内存耗尽。
比如如下代码:
package main
func TSlice() {
s := make([]int, 1000, 1000)
for index := range s {
s[index] = index
}
}
func main() {
TSlice()
}
使用go build -gcflags=-m进行分析:
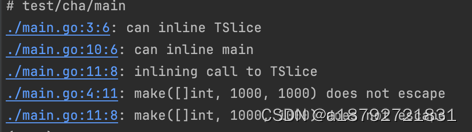
可以发现并没有出现逃逸,但是如果将上面的1000增加到100W呢:
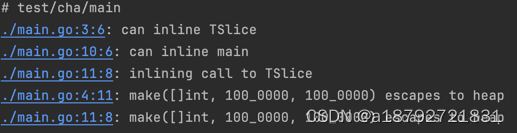
发现已经出现了逃逸现象。
当占空间不足以存放当前对象或无法判断当前切片长度时,会将对象分配到堆中。
2.3 动态类型逃逸
很多函数的参数类型为 interface 类型,比如 fmt.Println(a ...interface{}}),编译期间很难或无法确定参数的类型,也会产生逃逸:
package main
import "fmt"
func main() {
s := "test"
fmt.Println(s)
}
分析如下:
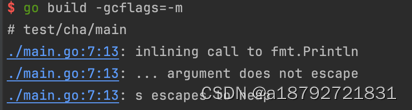
可以看到也出现了逃逸现象。
2.4 闭包引用对象逃逸
当出现闭包引用,那么就会出现逃逸:
package main
import "fmt"
func main() {
f := Fib()
for i := 0; i < 10; i++ {
fmt.Println(f())
}
}
func Fib() func() int {
a, b := 0, 1
return func() int {
a, b = b, a+b
return a
}
}
Fib函数返回一个func,在func中,对局部变量a,b进行引用和重新赋值,并且返回局部变量a,形成闭包。
在使用的时候,可以认为a,b类似全局变量,每次执行 a,b = b,a+b. 上面的代码和下面的代码原理相同
package main
import "fmt"
func main() {
a, b := 0, 1
for i := 0; i < 10; i++ {
a, b = b, a+b
fmt.Println(a)
}
}
但是Fib会导致a,b都发生逃逸
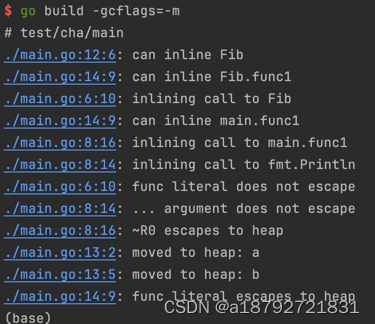
而a,b=b,a+b只会导致a逃逸
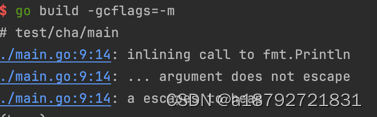
由于Fib中a,b的闭包引用,所以不得不将a,b都放在堆中。
3. 总结
- 栈上分配内存比在堆中分配内存有更高的效率。
- 栈上分配的内存不需要GC处理。
- 对上分配的内存使用完毕会交给GC处理。
- 逃逸分析的目的是决定分配地址是栈还是堆。
- 逃逸分析在编译阶段完成。
在编程的时候,应该尽可能避免产生内存逃逸。
传递指针可以减少底层值的赋值,可以提高效率,但是如果赋值的数据量小,由于指针传递会产生逃逸,则可能会使用堆,也可能增加GC的负担,所以指针传递不一定是高效的。