Go-知识string
string是Go语言中的基础数据类型,也是使用最广泛的类型。其实在编程语言中,字符串都基本上是使用最多的类型,而且编程语言都会做特殊处理。
1. string 的用法
1.1 string 的声明
在Go语言中声明一个字符串,有两种方式:
var s1 string
// 刚声明没有赋值,此时初值是 "" ,不是 nil ,因为字符串是基本数据类型,和 int 一样,有默认零值。
s1 = "hello"
// 还可以使用简短变量声明操作符声明
s2 := "world"
// 简短变量声明操作符等价于 声明+赋值
1.2 string 双引号和反单引号的区别
字符串既可以使用双引号赋值,也可以使用反单引号赋值(注意不是单引号),区别在于对特殊字符的处理。 比如,我们要赋值如下字符串:
Hello,
"World"!
如果使用双引号赋值:
s := "Hello,\n \"World!\""
如果使用反单引号赋值:
s := `Hello,
"World"!`
可以看到使用双引号,如果字符串中包含了双引号,那么就需要使用转义字符处理双引号,类似的,不仅是双引号,比如换行等特殊符号,需要使用\n特殊处理。
但是如果使用反单引号,那么对于特殊字符不需要做额外处理,即使是换行等特殊字符。
其实在别的编程语言中,都有类似的处理,比如Java中的文本域,也就是三个双引号开头,三个双引号结尾,中间就是文本域,不会对特殊字符做任何处理。
那么什么时候使用反单引号赋值呢?
这里推荐一个,如果是需要原封不动的给用户看,那么使用反引号比较好,这样代码中的内容,就是用户看到的呢。
1.3 string 拼接
字符串拼接可以使用 + 拼接:
s := "he" + "llo" + "!"
字符串拼接时会触发内存分配以及内存拷贝,单行语句拼接多个字符串只分配一次内存,在拼接时,会先计算最终字符串的长度在分配内存。
1.4 string 和 []byte 互转
字符串和字节数组之间互转:
[]byte转string:
func TestByteToString(t *testing.T) {
b := []byte{'H', 'e', 'l', 'l', 'o'}
s := string(b)
fmt.Println(s) // Hello
}
string转byte[]:
func TestStringToByte(t *testing.T) {
s := "hello"
b := []byte(s)
fmt.Println(b) // [72 101 108 108 111]
}
不管是string转[]byte还是[]byte转string,都会发生内存拷贝。
2. string 的特性
2.1 UTF编码
在Go里面string使用UTF-8编码存储字符串,如果是中文,那么就使用多个字节存储,所以在遍历字符串时,下标可能不连续。
比如如下代码:
func TestString(t *testing.T) {
s := "你好"
for i, v := range s {
fmt.Printf("%d:%c\n", i, v)
}
}
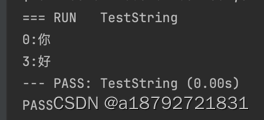
因为汉字使用两个字节存储,所以下标就不连续了。
如果是不常用汉字,占用的字节数可能更多,此时可能差的更多了。
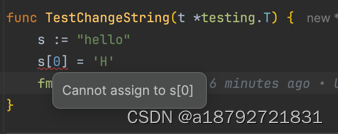
2.2 string 值不可修改
字符串可以为空,但是值不会是nil,而且字符串不允许修改值,只能赋值。
比如:
3. 标准库函数
标准库strings包中提供了大量的字符串操作函数,一些常用的如下:
| 函数 | 描述 |
func Contains(s, substr string) bool |
检查字符串s中是否包含子串substr |
func Split(s, sep string) []string |
将字符串s根据分隔符sep拆分并生成子串的切片 |
func Join(elems []string, sep string) string |
将字符串切面elems中的元素使用分隔符sep拼接成单个字符串 |
func HasPrefix(s, prefix string) bool |
检查字符串s是否包含前缀prefix |
func HasSuffix(s, suffix string) bool |
检查字符串s是否包含后缀suffix |
func ToUpper(s string) string |
将字符串s的所有字符转为大写 |
func ToLower(s string) string |
将字符串s的所有字符转为小写 |
func Trim(s string, cutset string) string |
将字符串s首部和尾部清除所有包含在字符集cutset中的字符 |
func TrimLeft(s string, cutset string) string |
将字符串s首部清除所有包含在字符集cutset中的字符 |
func TrimRight(s string, cutset string) string |
将字符串s尾部清除所有包含在字符集cutset中的字符 |
func TrimSpace(s string) string |
从字符串s首部和尾部清除所有空白字符 |
func TrimPrefix(s, prefix string) string |
清除字符串s中的前缀prefix |
func TrimSuffix(s, suffix string) string |
清除字符串s中的后缀suffix |
func Replace(s, old, new string, n int) string |
将字符串s中的前n个子串old替换成子串new |
func ReplaceAll(s, old, new string) string |
将字符串s中的所有子串old替换成子串new |
func EqualFold(s, t string) bool |
忽略大小写,比较两个子串是否相等 |
4. string 的实现原理
Go语言的标准库builtin中定义了string类型:

在注释中说明string是8字节的集合,通常是UTF-8编码的文本。 并且最后一行注释说明了: string可以为空,但是不会是nil。 string对象不可被修改
4.1 数据结构
在源码包的src/runtime/string.go#stringStruct中定义了string的数据结构:
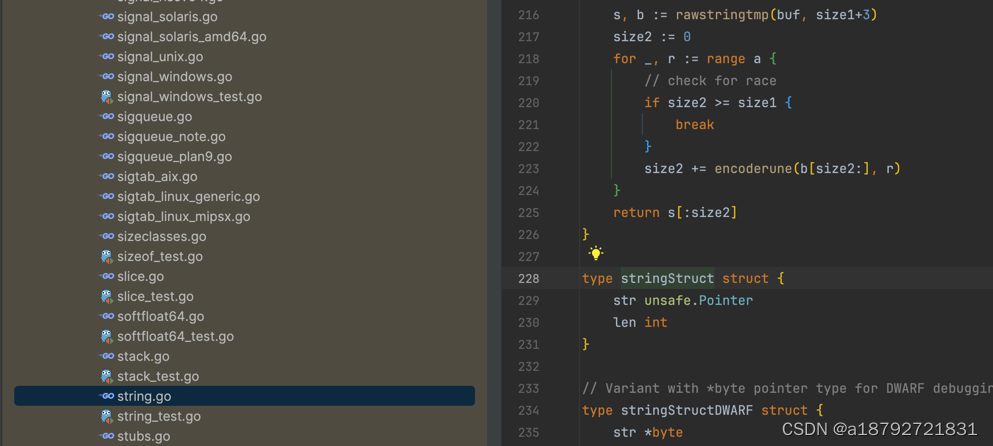
string的数据结构非常简单,只有两个字段: stringStruct.str:字符串的首地址;stringStruct.len:字符串的长度。
string的数据结构与切片类似,类似Java的字符数组。
在runtime包中使用函数gostringnocopy()生成字符串:
//go:nosplit
func gostringnocopy(str *byte) string {
ss := stringStruct{str: unsafe.Pointer(str), len: findnull(str)}
s := *(*string)(unsafe.Pointer(&ss))
return s
}
string生成时,先构建stringStruct对象,再转换成string。
4.2 编码
string使用Unicode编码存储字符,对于英文字符,一个字节就能存储,如果是别的字符,则使用多个字节存储Unicode编码值。
string的长度实际等于字节数,而不是真正的长度,比如
s := "你好"中的len(s)的值是6。
4.3 string 拼接
string拼接使用+进行拼接,即使有非常多的子串需要拼接,性能上也有比较好的保证,因为新string的内存空间是一次性分配完成的,所以性能消耗主要在拷贝数据上。
在runtime包中,使用concatstrings()函数拼接string:
// concatstrings implements a Go string concatenation x+y+z+...
// The operands are passed in the slice a.
// If buf != nil, the compiler has determined that the result does not
// escape the calling function, so the string data can be stored in buf
// if small enough.
func concatstrings(buf *tmpBuf, a []string) string {
// string的字符下标,因为一个字符可能是多字节存储
idx := 0
// 防止溢出,同时统计string的字节长度
l := 0
// 统计字符长度
count := 0
// 遍历统计数据 a 是切片
for i, x := range a {
// 统计单个string的字节长度
n := len(x)
// 如果字符为空,忽略,比如:""
if n == 0 {
continue
}
// 如果超过 l 的最大值,也就是 int 的最大值,那么就表示溢出了
// 如果是32位系统,那么最大值就是 int32=2147483647 ,如果是64位系统,那么最大值就是 int64=9223372036854775807
if l+n < l {
throw("string concatenation too long")
}
// 统计字节长度
l += n
// 统计切片个数
count++
// 移动字符下标
idx = i
}
// 如果传入的string都是空,那么返回空 ,比如 : a := "" + "" + ""
if count == 0 {
return ""
}
// If there is just one string and either it is not on the stack
// or our result does not escape the calling frame (buf != nil),
// then we can return that string directly.
// 如果只有一个切片,而且字符串在堆中,直接返回,比如 : a := a + ""
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
// 申请新的内存空间,并借助切片修改数据
s, b := rawstringtmp(buf, l)
// 遍历每一个 string
for _, x := range a {
// 拷贝数据,因为 s 和 b 的地址相同,所以修改 b 也是修改 s
copy(b, x)
// 移动 b 的指针到下一个空位
b = b[len(x):]
}
// 返回 s
return s
}
在一个拼接语句中,所有待拼接子串都被编译器组织到一个切片中,传入concatstrings,在拼接的过程中,
会对传入的切片统计总长度,然后根据总长度申请内存,在一一拷贝在一起返回。
如果传入的切片只有一个,那么直接返回,什么场景会是这种呢?
a := "x" + ""
因为""是空string,在统计中会忽略。
再看看 tmpBuf是个啥:
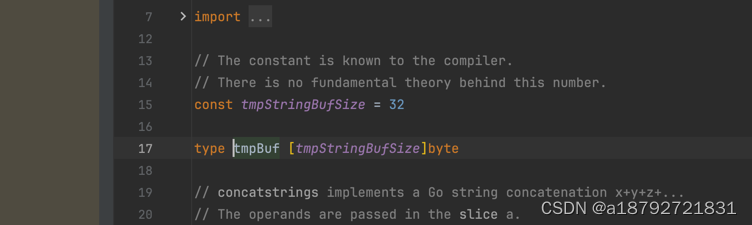
原来 tmpBuf是长度为32的字节数组。
接着看rawstringtmp函数,如果需要拷贝,新的string是通过这个函数申请的内存变量,然后通过返回的切片拷贝数据。
func rawstringtmp(buf *tmpBuf, l int) (s string, b []byte) {
// 如果目标地址不为空,而且 总长度小于等于 32
if buf != nil && l <= len(buf) {
// 去掉多余的长度,因为默认长度是 32 字节
b = buf[:l]
// 对内存做了处理,切片数组转为string
s = slicebytetostringtmp(&b[0], len(b))
} else {
// 如果长度大于 32 那么使用rawstring申请空间
s, b = rawstring(l)
}
return
上面的处理中,引入了两个新的函数slicebytetostringtmp和rawstring。
接着看slicebytetostringtmp函数:
func slicebytetostringtmp(ptr *byte, n int) (str string) {
// 如果 go run -race xx.go ,那么这里的 raceenabled = true , 对应的是 rice.go 文件
// 如果 go run xx.go 那么这里的 raceenabled = false, 对应的是 rice0.go 文件
// rice 是读写检测,用于并发变量的冲突检测,开启后性能变慢
if raceenabled && n > 0 {
racereadrangepc(unsafe.Pointer(ptr),
uintptr(n),
getcallerpc(),
funcPC(slicebytetostringtmp))
}
// 这个也是编译优化 -msan 的检测,好像是内存清理相关的优化
if msanenabled && n > 0 {
msanread(unsafe.Pointer(ptr), uintptr(n))
}
// 设置string地址
stringStructOf(&str).str = unsafe.Pointer(ptr)
// 设置string字节长度
stringStructOf(&str).len = n
return
}
接着看看rawstring函数:
func rawstring(size int) (s string, b []byte) {
// 申请内存
p := mallocgc(uintptr(size), nil, false)
// 设置string地址
stringStructOf(&s).str = p
// 设置string字节长度
stringStructOf(&s).len = size
// 从地址取出数据并进行格式转换
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, size}
return
}
4.4 []byte 转 string
byte切片转为string:
func TestByteSliceToString(t *testing.T) {
b := []byte{'H', 'e', 'l', 'l', 'o'}
s := string(b)
fmt.Println(s)
}
在string.go中,函数slicebytetostring实现的:
func slicebytetostring(buf *tmpBuf, ptr *byte, n int) (str string) {
// 如果字节切片的长度为0,返回string的零值 ""
if n == 0 {
return ""
}
// 是否开启 -race
if raceenabled {
racereadrangepc(unsafe.Pointer(ptr),
uintptr(n),
getcallerpc(),
funcPC(slicebytetostring))
}
// 是否开启 -msan
if msanenabled {
msanread(unsafe.Pointer(ptr), uintptr(n))
}
// 如果字节切片的长度为1,那么直接查表,找到对应的字符
if n == 1 {
p := unsafe.Pointer(&staticuint64s[*ptr])
if sys.BigEndian {
p = add(p, 7)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
// 如果长度小于32,不用申请空间(函数调用的时候,会给buf分配32的长度)
if buf != nil && n <= len(buf) {
p = unsafe.Pointer(buf)
} else {
// 如果超过32,那么申请内存空间
p = mallocgc(uintptr(n), nil, false)
}
// 构造 string 结构
stringStructOf(&str).str = p
stringStructOf(&str).len = n
// 内存拷贝
memmove(p, unsafe.Pointer(ptr), uintptr(n))
return
}
需要注意的是 []byte 转 string 需要内存拷贝。
4.5 string 转 []byte
string转为[]byte:
func TestStringToSlice(t *testing.T) { s := "Hello" b := []byte(s) fmt.Println(b) }在
string.go中,通过函数stringtoslicebyte转换:func stringtoslicebyte(buf *tmpBuf, s string) []byte { var b []byte // 如果 buf 不为空,且string字节长度小于32,那么不需要额外申请空间 if buf != nil && len(s) <= len(buf) { // 重新赋值 buf,相当于清空上一次数据 *buf = tmpBuf{} // 利用切片操作,初始化 b 字节数组 b = buf[:len(s)] } else { // 否则重新申请内存空间 b = rawbyteslice(len(s)) } // 内存拷贝 copy(b, s) return b }可以看到,如果长度大于32,就会触发使用
rawbyteslice函数重新申请内存空间:func rawbyteslice(size int) (b []byte) { // 首先会对需要的长度做个计算,向上取值,取一个page的大小,只会多不会少 cap := roundupsize(uintptr(size)) // 申请内存 p := mallocgc(cap, nil, false) // 内存对齐?不太明白这里是干啥的 if cap != uintptr(size) { memclrNoHeapPointers(add(p, uintptr(size)), cap-uintptr(size)) } // 类型转换 *(*slice)(unsafe.Pointer(&b)) = slice{p, size, int(cap)} return }4.6 []byte 转为 string 的编译优化
有时候可能只是临时需要将 []byte 转为 string ,如果每次都进行内存数据拷贝,那么运行性能就下来了。
为了保证性能,会进行优化,stringStruct构造的时候,直接将 []byte 的地址作为stringStruct的地址,避免内存拷贝,以此加快速度。
常见的场景有:
m[string(b)]: 用[]byte找map中的string的key"a"+"b"+"c": string 拼接string(b) == "Hello": string 比较
5. 总结
5.1 为什么Go里面string不允许修改
在Go语言的设计中, string 通常指的是字符串的字面量,而且字符串一般情况下存储的位置也是只读,而不是堆或者栈(这里可能一定程度上借鉴了汇编之类的语言)。
所以设计为string不可修改。
当string不可修改后,带来的好处是string变得非常轻量,而且可以放心的在go-routine中进行传递,不用考虑并发冲突和内存拷贝。
5.2 什么时候使用string,什么时候使用[]byte
string和[]byte都可以表示字符串,但是因为数据结构不同,提供的能力也不同:
string 擅长的场景:
- 字符串比较
- 不需要nil
[]byte 擅长的场景:
- 修改字符串的场景
- 函数返回值等需要nil
- 需要切片操作
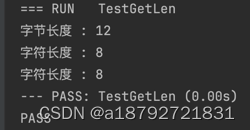
5.3 string 获取长度
在string中有两个长度有意义:字符长度和字节长度。
一般使用len(s)获取的是字节长度,那么如何获取字符长度呢?
func TestGetLen(t *testing.T) {
s := "hello,你好"
length := len(s)
fmt.Printf("字节长度 : %d\n", length)
// rune 是针对 unicode 做适配的字节类型长度为 int32 , byte 长度为 uint8
chLen := len([]rune(s))
fmt.Printf("字符长度 : %d\n", chLen)
chLen1 := utf8.RuneCountInString(s)
fmt.Printf("字符长度 : %d\n", chLen1)
}