mysql 存储过程详解
mysql 语法中文文档:https://www.mysqlzh.com/
存储过程文档:https://www.mysqlzh.com/doc/223.html
1. 介绍
MySQL 5.1版支持存储程序和函数。一个存储程序是可以被存储在服务器中的一套SQL语句。一旦它被存储了,客户端不需要再重新发布单独的语句,而是可以引用存储程序来替代。
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。
存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用。
存储过程可以理解为封装的一个方法,和java中封装的方法一样。只是这个方法是用sql实现,而且存储在mysql中,也只能在sql语句中调用。
2. 特点
2.1 优点
- 存储过程可封装,并隐藏复杂的商业逻辑。
- 存储过程可以回传值,并可以接受参数。
- 存储过程无法使用 SELECT 指令来运行,因为它是子程序,与查看表,数据表或用户定义函数不同。
- 存储过程可以用在数据检验,强制实行商业逻辑等。
- 存储程序可以提供改良后的性能,因为只有较少的信息需要在服务器和客户算之间传送。代价是增加数据库服务器系统的负荷,因为更多的工作在服务器这边完成,更少的在客户端(应用程序)那边完成上。
2.2 缺点
- 存储过程,往往定制化于特定的数据库上,因为支持的编程语言不同。当切换到其他厂商的数据库系统时,需要重写原有的存储过程。
- 存储过程的性能调校与撰写,受限于各种数据库系统。
3. 权限
- 创建存储过程需要CREATE ROUTINE权限。
- 修改或移除存储过程需要ALTER ROUTINE权限。
- 执行存储过程需要EXECUTE权限。
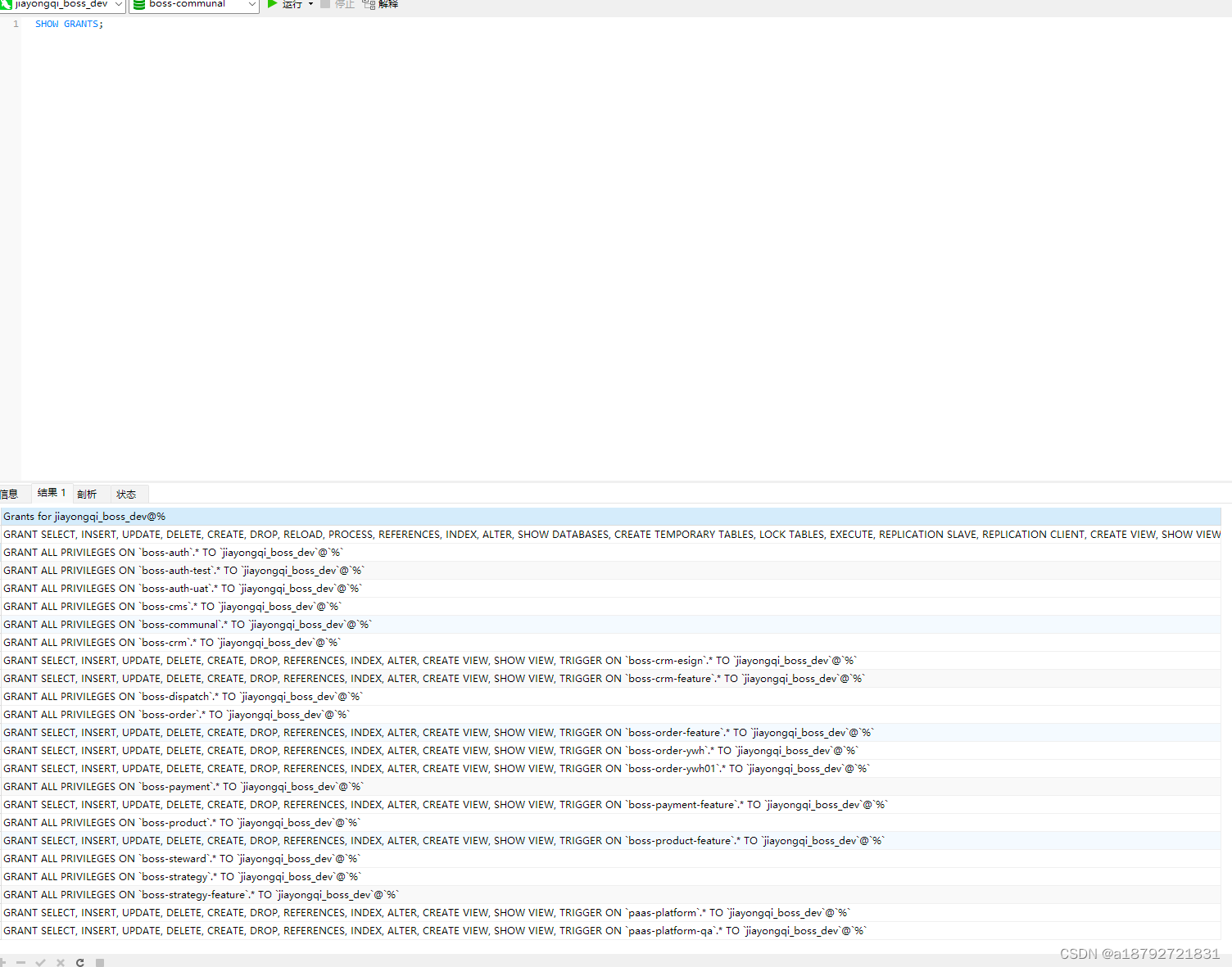
查看权限
SHOW GRANTS [FOR user]
如果不指定user,就是查询当前登陆用户的权限:
4. 语法
4.1 创建存储过程
CREATE PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...] routine_body
proc_parameter:
[ IN | OUT | INOUT ] param_name type
characteristic:
LANGUAGE SQL
| [NOT] DETERMINISTIC
| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
routine_body:
Valid SQL procedure statement or statements
创建存储过程默认绑定当前窗口所在的数据库,即
db_name.sp_name。如果需要绑定到特定的数据,需要在
sp_name前 指定数据库。如果存储过程的名字和
mysql实现的名字相同,那么需要在sp_name和(中间插入 空格。(尽可能避免)
-
参数列表是可选的,可以没有参数。
参数需要指定是输入数据,还是输出数据。
参数需要设置名字。
参数需要指定类型。(任意mysql原生的类型)
-
存储过程限定
这个限定使用较少,几乎都是不设置的。
CONTAINS SQL表示子程序不包含读或写数据的语句。NO SQL表示子程序不包含SQL语句。READS SQL DATA表示子程序包含读数据的语句,但不包含写数据的语句。MODIFIES SQL DATA表示子程序包含写数据的语句。如果这些特征没有明确给定,默认的是CONTAINS SQL。
SQL SECURITY { DEFINER INVOKER }是指存储过程是否只能由定义者的权限调用,这里也就是第三节中说的 EXECUTE权限.COMMENT是注释。
-
存储过程逻辑
是一个sql的代码块,由begin 开始,end结束。
4.2 sql代码块
代码块主要是封装一块整体的逻辑。
[begin_label:] BEGIN
[statement_list]
END [end_label]
- begin_label 是给sql代码块取个标签,一般用在有提前跳出循环,或者提前结束的地方。使用在其他场景也有,但是会破坏程序执行的顺序性和确定性,不推荐使用。
- begin_label 和 end_label ,end_label 可以省略,但是当end_label 存在的时候,begin_label必须存在。
4.3 例子
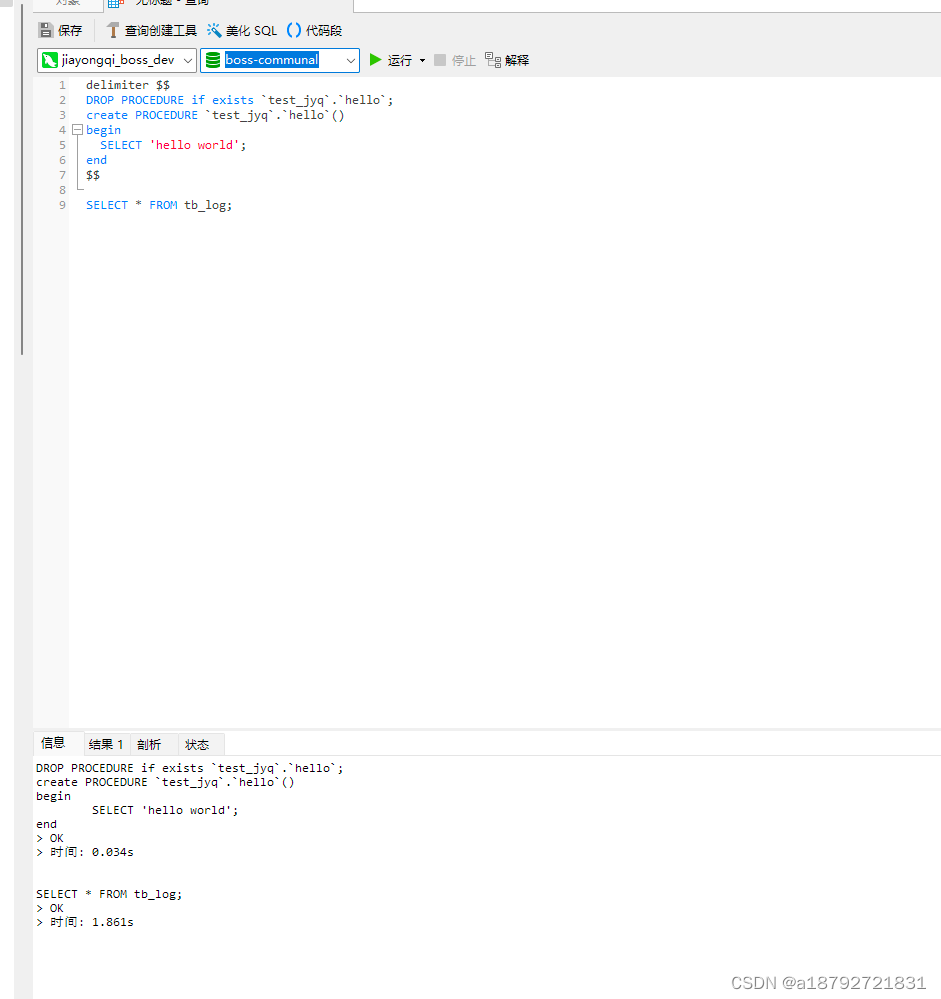
存储过程的 helloWorld
delimiter $$
DROP PROCEDURE if exists `test_jyq`.`hello`;
create PROCEDURE `test_jyq`.`hello`()
begin
SELECT 'hello world';
end
$$
delimiter ;
解析
首先替换sql语句结束符,从;替换为$$,也就是遇到$$才认为是语句结束了。
接着先删除存储过程。否则可能出现存储过程已存在的问题。
创建存储过程,(不支持 not exists语法),指定数据库,名字和参数
接着是sql代码块
最后是调用新的sql语句结束符,将两个结束符之间的内容作为一个整体发送到服务端。
最后切换回;作为语句结束符。
需要注意的是,对于存储过程,最好不要使用sql美化。
原因
mysql 是客户端,服务端应用程序,用户在客户端上编辑作业,然后客户端将作业网络传输到服务端,服务端执行后,将结果返回客户端。
mysql 默认语法结束符是 ;,在执行的时候,客户端每次遇到;就认为一条sql语句结束了,需要将上一个;和这一个;之间的字符作为一个完整的语句发送到服务端。
但是因为存储过程是很多个语句的集合,因此在存储过程最开的时候,使用delimiter关键词,将mysql 的语句结束符号,临时换为其他符号。
在储存过程结束的后面,调用新设置的语句结束符,将两次语句结束符之间的内容,作为一个整体,发送到服务端。
最后在使用delimiter将语句结束符切换回;。
因为中间替换了语句结束符,但是客户端工具可能不支持delimiter,就会依然用;作为语句结束符,从而出现存储过程逻辑错误。
如果最后忘记切换回
;会出现什么?经过验证,对于
;你还是可以继续使用的,其他的符号,就不一定了,所以,最好不要忘记切换回来。
4.4 调用
调用存储过程,首先需要有存储过程的 调用 权限。
call [db_name.]sp_name([params]);

4.5 编辑或修改存储过程特性
需要注意的是,修改或者编辑的是存储过程的特性,不是存储过程的逻辑
ALTER {PROCEDURE | FUNCTION} sp_name [characteristic ...]
characteristic:
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }
| SQL SECURITY { DEFINER | INVOKER }
| COMMENT 'string'
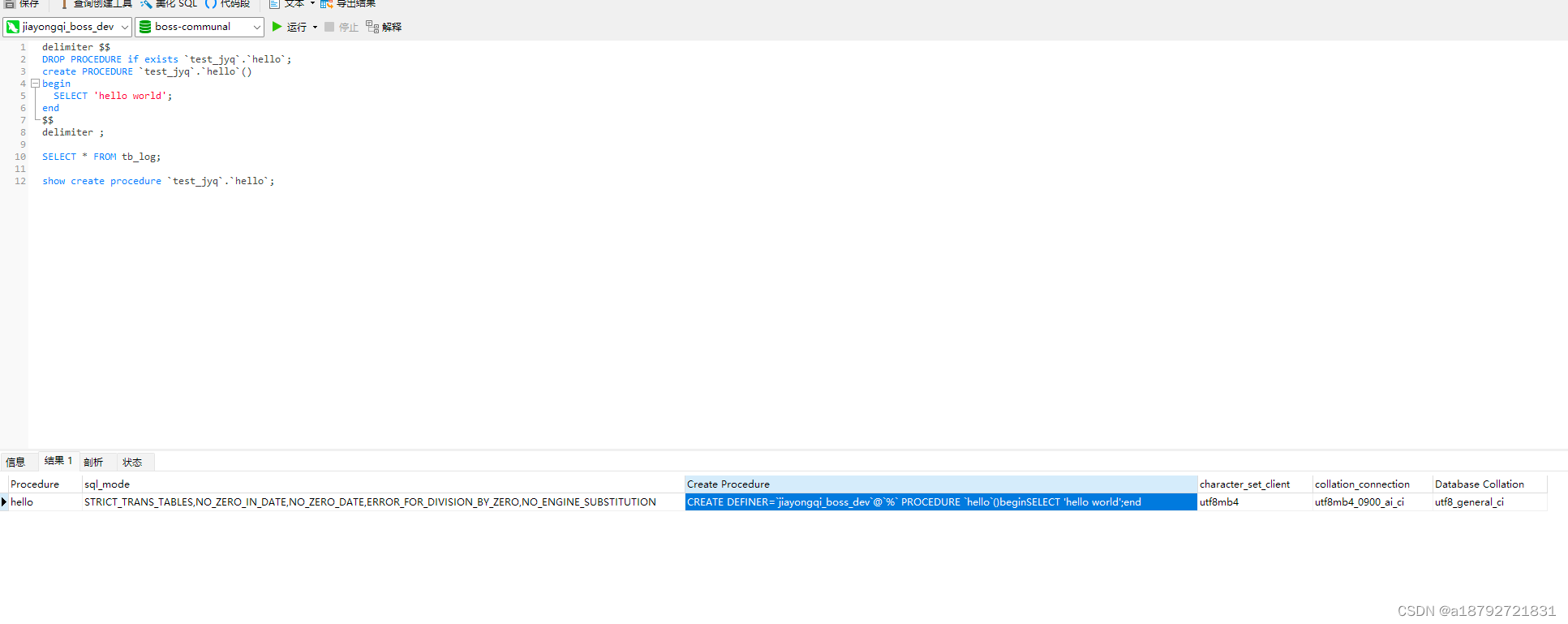
4.6 查看存储过程逻辑
展示存储过程的详细信息,包含逻辑
SHOW CREATE PROCEDURE [db_name.]sp_name
4.7 查看存储过程特征
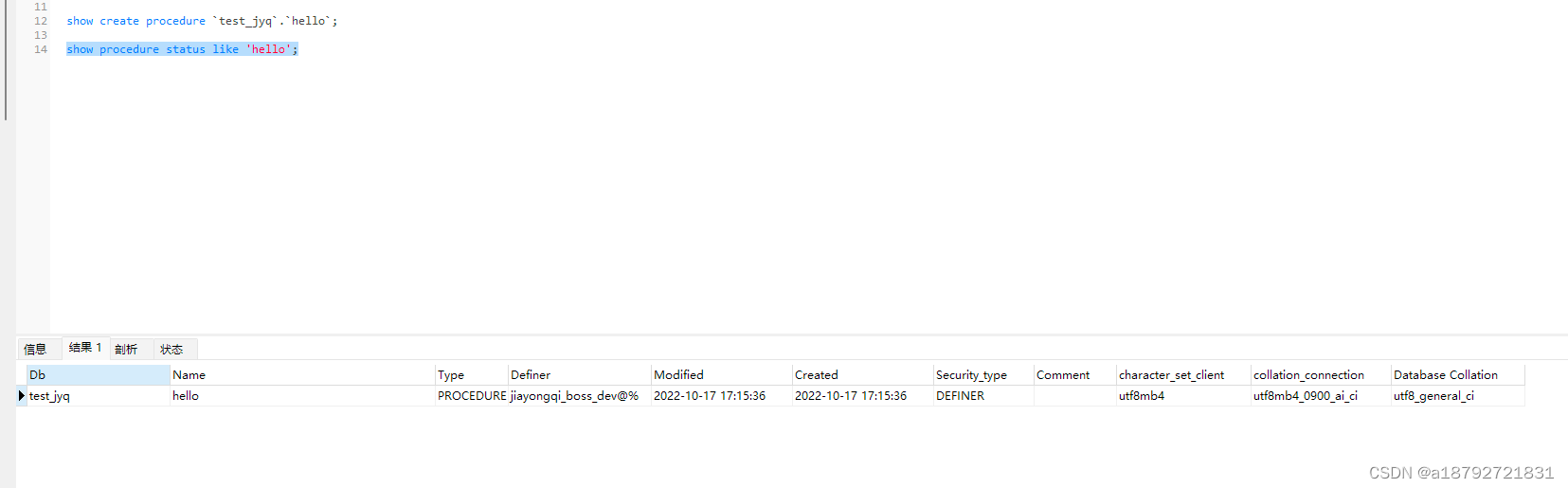
展示存储过程的扩展信息。
返回存储过程的特征,如数据库,名字,类型,创建者及创建和修改日期。如果没有指定样式,根据你使用的语句,所有 存储程序和所有存储函数的信息都被列出。
SHOW PROCEDURE STATUS [LIKE 'pattern']
实际是查询
INFORMATION_SCHEMA.ROUTINES表。
4.8 删除存储过程
需要有删除权限
DROP PROCEDURE [IF EXISTS] [db_name.]sp_name
4.9 存储过程中的变量
在存储过程中可能会用到变量,整合不同的逻辑,特别是复杂逻辑。
用户变量名在sql中一般是大小写不敏感的。
4.9.1 局部变量 declare
语法
DECLARE var_name[,...] type [DEFAULT value]
这个语句被用来声明局部变量。要给变量提供一个默认值,请包含一个DEFAULT子句。值可以被指定为一个表达式,不需要为一个常数。如果没有DEFAULT子句,初始值为NULL。
局部变量的作用范围在它被声明的BEGIN … END块内。它可以被用在嵌套的块中,除了那些用相同名字 声明变量的块。(begin_label,还记得吗)
4.9.2 变量SET语句
语法
SET var_name = expr [, var_name = expr] ...
需要注意的是,使用set一般都是设置常量等确定的值。
4.9.3 SELECT … INTO语句
语法
SELECT col_name[,...] INTO var_name[,...] table_expr
查询结果返回值只有单一行才成功,否则异常失败。
如果在查询中,存在变量名和查询结果列名相同的场景,那么优先取变量名。
举例:
delimiter $$
drop procedure if exists sp1;
CREATE PROCEDURE sp1 (x VARCHAR(5))
BEGIN
DECLARE xname VARCHAR(5) DEFAULT 'bob';
DECLARE newname VARCHAR(5);
DECLARE xid INT;
-- 不管 select 结果返回如何,xname 永远等于 bob
SELECT xname,id INTO newname,xid
FROM table1 WHERE xname = xname;
-- 换句话说,where 后面一定等于 true
-- 可以通过取别名的方式来解决
SELECT newname;
END;
$$
delimiter ;
4.9.4 变量的使用
使用变量名即可,比如
delimiter $$
drop procedure if exists sp1;
CREATE PROCEDURE sp1 (x VARCHAR(5))
BEGIN
DECLARE xname VARCHAR(5) DEFAULT 'bob';
DECLARE newname VARCHAR(5);
DECLARE xid INT;
SELECT xname,id INTO newname,xid
FROM table1 WHERE xname = xname;
SELECT newname;
# 变量的使用
END;
$$
delimiter ;
4.10 条件和处理
在复杂的逻辑中,总是存在一些特定的场景,而且这些特定的场景需要特定的逻辑解决,同时遇到特定的场景,可能还需要特定的执行顺序。
4.10.1 条件
声明场景(类似 java 中 方法中的 throws 语句)
DECLARE condition_name CONDITION FOR condition_value
condition_value:
SQLSTATE [VALUE] sqlstate_value
| mysql_error_code
SQLSTATE 是mysql 的执行结果,类似http 请求状态码。参考:https://www.cnblogs.com/mqxs/p/6019992.html
4.10.2 处理
处理逻辑
DECLARE handler_type HANDLER FOR condition_value[,...] sp_statement
handler_type:
CONTINUE
| EXIT
| UNDO
condition_value:
SQLSTATE [VALUE] sqlstate_value
| condition_name
| SQLWARNING
| NOT FOUND
| SQLEXCEPTION
| mysql_error_code
- handler_type:处理的类型:CONTINUE->继续执行,EXIT->结束,UNDO->不支持
- condition_value:sql执行状态,异常码,执行速记码(SQLWARNING:01开头的异常码;NOT FOUND:02开头的码;SQLEXCEPTION:异常码)
- condition_value还可以是4.9.1中定义的名字
- sp_statement:处理逻辑
4.10.3 例子
申明+处理
delimiter $$
DROP PROCEDURE if exists `test_jyq`.`hello`;
create PROCEDURE `test_jyq`.`hello`()
begin
declare data_not_found CONDITION FOR sqlstate '02000';
declare continue HANDLER FOR data_not_found SELECT 'data not found';
SELECT 'x' into @y from dual where 1 = 2;
end
$$
delimiter ;
call `test_jyq`.`hello`();
执行结果:
因为 select 'x' into @y from dual where 1=2中,where条件不成立,因此select查询结果为空,而 into则要求结果是单一的一行,此时,sqlstate就是02000也就是 not found。
这种适合大型的存储过程,统一定义异常,统一处理异常。
还有一种比较简单的,不使用声明,只使用定义。
delimiter $$
DROP PROCEDURE if exists `test_jyq`.`hello`;
create PROCEDURE `test_jyq`.`hello`()
begin
declare continue HANDLER for not found select 'data not found 2';
SELECT 'x' into @y from dual where 1 = 2;
end
$$
delimiter ;
call `test_jyq`.`hello`();
执行结果
4.11 游标
在4.8小节中,我们了解到针对单个数据的变量的创建和使用。那么针对多个数据的一个结果集,我们创建那么多的变量是一件很浪费资源的事情。
游标就是针对多条数据的一个结果集的封装。需要注意的是,一个结果集,意味着结果集内数据的格式相同,具有相同的字段,相同的列。列或字段的值可不同。
游标仅仅在存储过程和函数内支持。
游标创建后只读。
游标创建后,执行的时候,在游标处理逻辑之前被执行。
4.11.1 游标声明
语法
DECLARE cursor_name CURSOR FOR select_statement
游标的名字不能重复。
游标的
select_statement中不能有INTO语句。游标需要放在变量声明之后,否则会出现 1337 错误。
HANDLER 声明要在游标之前,否则也会出现错误。
4.11.2 打开游标
打开游标实际上是重置之前使用这个游标的状态。比如将索引移动到开始。
游标是可以重复使用的,因为游标只读。
语法:
OPEN cursor_name
4.11.3 读取游标
如果当前行有数据,读取当前数据,并将索引移动到下一行。否则结束。
FETCH cursor_name INTO var_name [, var_name] ...
通常配合into 将取出行的值赋值给变量。
而且还配合循环处理,处理每一条数据。
非强制一一对应。
4.11.4 关闭游标
释放数据集,删除游标。
语法
CLOSE cursor_name
如果不显示关闭,那么在sql语句块(begin-end)执行结束,自动关闭。
4.11.5 例子
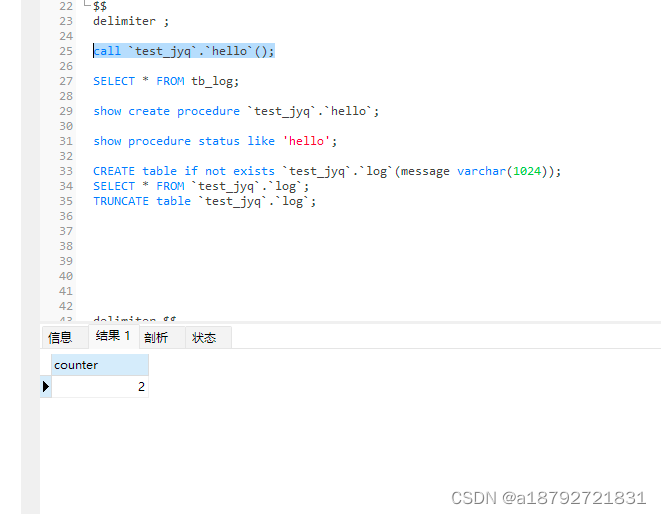
统计查询条数,也就是手写一个count函数
delimiter $$ /* 替换结束符 */
DROP PROCEDURE if exists `test_jyq`.`hello`; /* 删除存储过程 */
create PROCEDURE `test_jyq`.`hello`() /* 定义存储过程 */
begin /* 逻辑块开始 */
declare id int DEFAULT 0; /* 游标列读取变量 */
declare sid char(20) DEFAULT ''; /* 游标列读取变量 */
declare done int DEFAULT 0; /* 游标循环标志 */
declare counter int DEFAULT 0; /* 计数器 */
declare cur CURSOR for SELECT uid, CONCAT(uid, ' ', uid) as suid FROM (SELECT 1 as uid UNION SELECT 2 as uid) t;
/* 游标定义 */
declare continue HANDLER for not found set done = 1;
/* 异常处理,同时也是游标退出操作,循环跳出点 */
open cur; /* 打开游标 */
repeat /* 重复读取游标 */
fetch cur into id, sid; /* 读取游标数据,并赋值到指定变量 */
if not done then /* 循环标识检测 */
set counter = counter + 1; /* 循环逻辑 */
end if;
UNTIL done end repeat; /* 循环跳出 */
close cur; /* 关闭游标 */
select counter; /* 打印结果 */
end /* 逻辑块结束 */
$$ /* 结束符调用 */
delimiter ; /* 结束符还原 */
执行:
4.11.6 游标重复使用
游标关闭后,重新打开,就可以重复使用了
delimiter $$ /* 替换结束符 */
DROP PROCEDURE if exists `test_jyq`.`hello`; /* 删除存储过程 */
create PROCEDURE `test_jyq`.`hello`() /* 定义存储过程 */
begin /* 逻辑块开始 */
declare id int DEFAULT 0; /* 游标列读取变量 */
declare sid char(20) DEFAULT ''; /* 游标列读取变量 */
declare done int DEFAULT 0; /* 游标循环标志 */
declare counter int DEFAULT 0; /* 计数器 */
declare cur CURSOR for SELECT uid, CONCAT(uid, ' ', uid) as suid FROM (SELECT 1 as uid UNION SELECT 2 as uid) t;
/* 游标定义 */
declare continue HANDLER for not found set done = 1;
/* 异常处理,同时也是游标退出操作,循环跳出点 */
open cur; /* 打开游标 */
repeat /* 重复读取游标 */
fetch cur into id, sid; /* 读取游标数据,并赋值到指定变量 */
if not done then /* 循环标识检测 */
set counter = counter + 1; /* 循环逻辑 */
end if;
UNTIL done end repeat; /* 循环跳出 */
close cur; /* 关闭游标 */
set done = 0; /* 重置循环标志 */
open cur; /* 重新打开游标 */
repeat /* 重复读取游标 */
fetch cur into id, sid; /* 读取游标数据,并赋值到指定变量 */
if not done then /* 循环标识检测 */
set counter = counter + 1; /* 循环逻辑 */
end if;
UNTIL done end repeat; /* 循环跳出 */
close cur; /* 关闭游标 */
select counter; /* 打印结果 */
end /* 逻辑块结束 */
$$ /* 结束符调用 */
delimiter ; /* 结束符还原 */
执行结果:
4.12 流程控制
逻辑中存在各种各样的场景对应的操作,不同的场景需要执行不同的逻辑,所以就需要对执行流程的顺序进行控制。
4.12.1 IF语句
语法
IF search_condition THEN statement_list
[ELSEIF search_condition THEN statement_list] ...
[ELSE statement_list]
END IF
和 java 的 if 一样的啦。
4.12.2 CASE 语句
语法
CASE case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] ...
[ELSE statement_list]
END CASE
和 java 的 switch 一样。
CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] ...
[ELSE statement_list]
END CASE
4.12.3 LOOP 语句
语法
[begin_label:] LOOP
statement_list
END LOOP [end_label]
等价 java 的 while(true).需要显示的跳出语句。
4.12.4 LEAVE 语句
语法
LEAVE label
类似 c 语言中的 goto
4.12.5 ITERATE 语句
语法
ITERATE label
ITERATE只可以出现在LOOP, REPEAT, 和WHILE语句内。ITERATE意思为:“再次循环”
类似 java 中 continue label_name;
4.12.6 REPEAT 语句
语法
[begin_label:] REPEAT
statement_list
UNTIL search_condition
END REPEAT [end_label]
REPEAT语句内的语句或语句群被重复,直至search_condition 为真。
类似 java 的 do-while
4.12.7 WHILE 语句
语法
[begin_label:] WHILE search_condition DO
statement_list
END WHILE [end_label]
WHILE语句内的语句或语句群被重复,直至search_condition 为真。
类似 java 中的 while ,需要与 LOOP 区别。
4.13 调试
我们写好了一个存储过程,结果发现并没有如我们期望的执行,那么该如何调整呢?
mysql并不像oracle 有 plsql 工具,可以用于调试sql。
而且mysql 本身也并不支持类似 oracle 的 控制台输出函数 dbms_output 。
因此mysql 调试实际上是比较困难的一件事情。
但是办法总是比困难多。
调试是借助 insert 语句,将存储过程执行中变量的值记录下来,并不是打断点调试。
首先创建一个记录表,记录表的结构根据需要定义。
CREATE table if not exists `test_jyq`.`log`(message varchar(1024));
接着在存储过程中,需要查看变量值的地方,将变量的值写入记录表。
delimiter $$
DROP PROCEDURE if exists `test_jyq`.`hello`;
create PROCEDURE `test_jyq`.`hello`()
begin
declare id int DEFAULT 0;
declare sid char(20) DEFAULT '';
declare done int DEFAULT 0;
declare counter int DEFAULT 0;
declare cur CURSOR for SELECT uid, CONCAT(uid, ' ', uid) as suid FROM (SELECT 1 as uid UNION SELECT 2 as uid) t;
declare continue HANDLER for not found set done = 1;
open cur;
repeat
fetch cur into id, sid;
if not done then
insert into `test_jyq`.`log`(message) values (CONCAT(id, ''));
insert into `test_jyq`.`log`(message) values (sid);
insert into `test_jyq`.`log`(message) values (CONCAT(counter, ''));
insert into `test_jyq`.`log`(message) values (CONCAT(done, ''));
set counter = counter + 1;
end if;
UNTIL done end repeat;
close cur;
select counter;
end
$$
delimiter ;
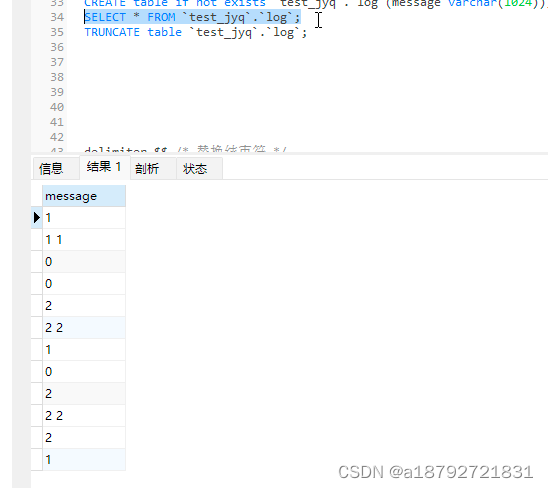
call `test_jyq`.`hello`();
调试日志:
5. 总结
mysql 的存储过程和 Java 的方法不管从使用或者定义上,都是很像的,解决的问题也是差不多的。
mysql 的存储过程,除了控制权限,还能封装一些涉密逻辑。不过,一般很少会将业务逻辑写入数据库层面。
了解了mysql 的存储过程,也许能帮你解决大问题。